A Jornada de Claude rumo à loucura em diagramas: O custo da economia, ou como a conta da API aumentou 100 vezes
Há alguns dias, Stella Laurenzo, diretora de IA da AMD, publicou um problema intitulado «Claude Code Unusable for Complex Engineering Tasks» no repositório oficial do Claude Code. Não se tratava de uma reclamação emocional de um utilizador, mas sim de uma análise quantitativa baseada em 6 800 sessões. Isso trouxe à tona a questão que a comunidade de IA mais reluta em enfrentar, com um conjunto de números a destacar-se particularmente: uma alteração na configuração feita pela Anthropic com o objetivo de reduzir custos fez com que a fatura mensal da API desta equipa disparasse de 345 dólares para 42 121 dólares.
A equipa de Laurenzo registou 235 000 chamadas à ferramenta, 18 000 solicitações e documentou a degradação sistémica do desempenho do Claude Code desde fevereiro de 2026. Esta notícia foi posteriormente divulgada pelo The Register, desencadeando uma onda de reações na comunidade de programadores que durou duas semanas.
Boris Cherny, chefe da equipa do Anthropic Claude Code, deu uma explicação no Hacker News. A 9 de fevereiro, com o lançamento do Opus 4.6, foi ativado por predefinição um mecanismo de «pensamento autónomo», no qual o modelo decide de forma autónoma a duração do pensamento. A 3 de março, a Anthropic reduziu então o esforço de raciocínio predefinido para 85. A explicação oficial foi «o ponto de equilíbrio ideal entre inteligência, latência e custo». O impacto real destes dois ajustes é evidente a partir dos dados.
A profundidade do pensamento diminui em três quartos
De acordo com os dados da issue no GitHub de Stella Laurenzo, a profundidade média de raciocínio do Claude Code sofreu uma queda em três fases ao longo de dois meses: de um máximo de 2 200 caracteres no final de janeiro para 720 caracteres no final de fevereiro, o que representa uma queda de 67 %. Em março, tinha diminuído ainda mais para 560 caracteres, o que representa uma redução de 75% em relação ao pico.
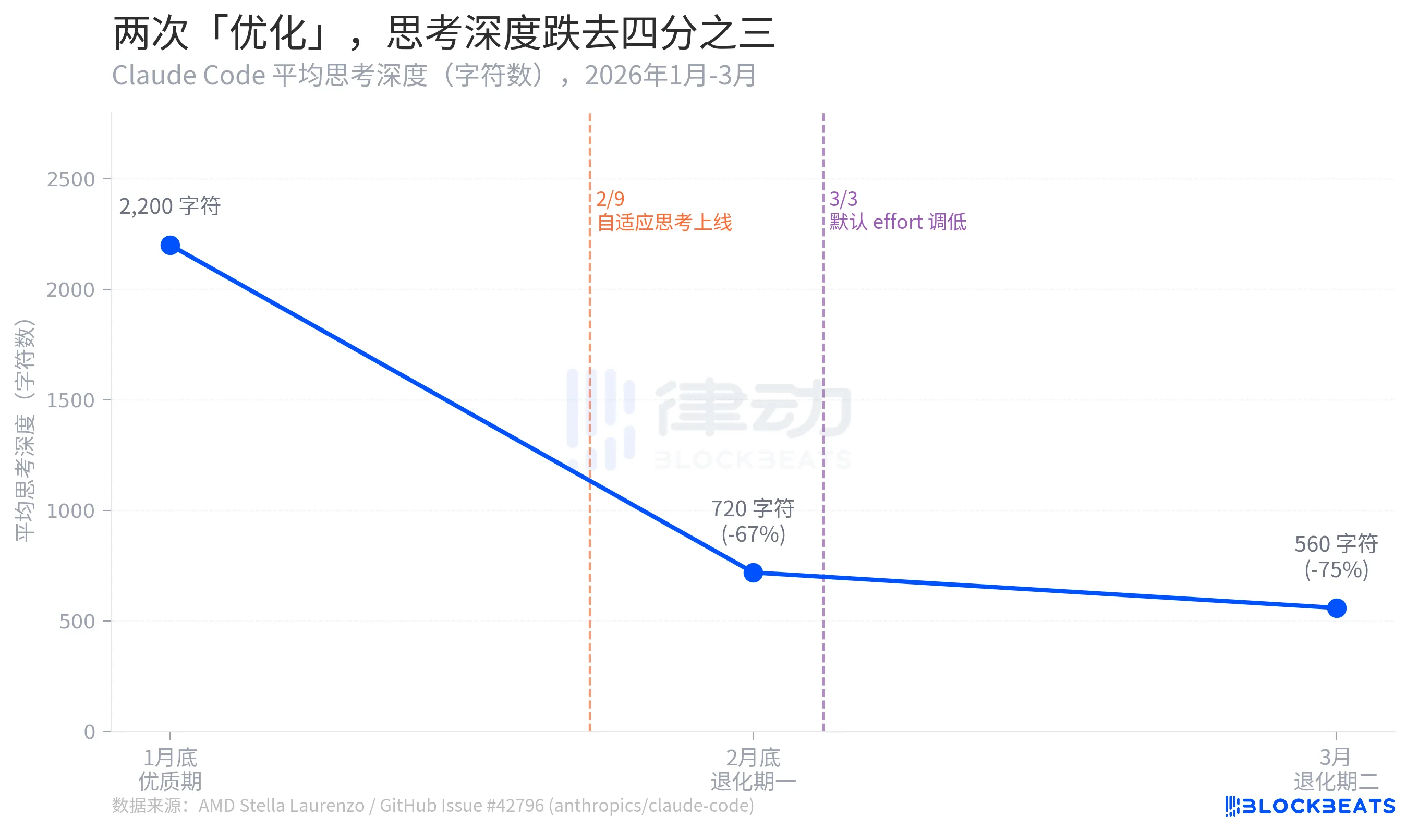
A profundidade de reflexão, neste contexto, é uma métrica indicativa que reflete o grau de «deliberação interna» que o modelo está disposto a realizar antes de fornecer uma resposta. A diferença entre 2 200 e 560 caracteres equivale, grosso modo, a passar de «redigir antes de responder» para «pensar dois segundos antes de falar».
Laurenzo também salientou que a funcionalidade «Thought Content Redaction» (redact-thinking-2026-02-12), lançada no início de março, ocultou coincidentemente o processo de raciocínio do modelo durante esse período, tornando a redução menos percetível para os utilizadores. Boris Cherny insiste que se tratou apenas de uma alteração na interface do utilizador e que não afetou o raciocínio subjacente. Ambas as afirmações são tecnicamente válidas, mas, do ponto de vista do utilizador, o efeito é indistinguível.
Boris Cherny reconheceu posteriormente que, mesmo ao redefinir manualmente o esforço para o máximo, o mecanismo de raciocínio automático poderia ainda assim atribuir um nível insuficiente de raciocínio em algumas iterações, levando a conteúdos alucinatórios. «Restaurar o esforço máximo» não é uma solução completa; limita-se a voltar a colocar o regulador mais próximo da sua posição original, em vez de restaurar o seu determinismo original.
De «Programador Orientado para a Investigação» a «Programador de Edição à Cega»
Um pormenor no relatório de Stella Laurenzo é mais revelador do que a profundidade do raciocínio: quantos ficheiros relevantes a modelo lê ativamente antes de introduzir alterações no código.
De acordo com os dados das issues do GitHub, durante o período de maior atividade, a relação média entre leituras e edições é de 6,6. Antes de efetuar uma alteração no código, o modelo, em média, analisa 6,6 ficheiros para compreender o contexto. Durante o período de decaimento, este valor desce para 2,0, o que representa uma redução de 70%. Mais importante ainda, cerca de um terço das edições de código ocorrem sem que o modelo leia o ficheiro de destino, passando diretamente à ação.
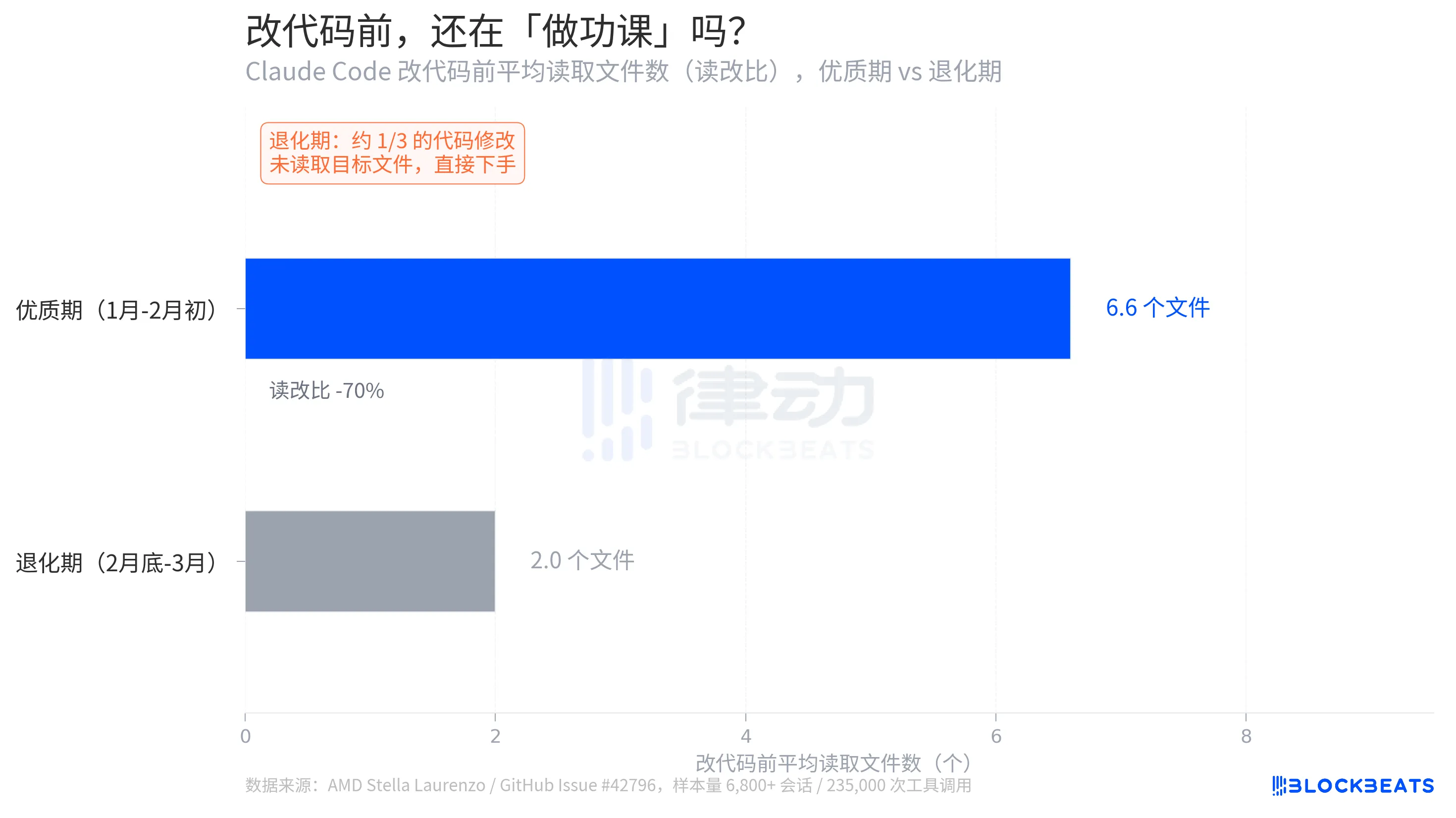
Laurenzo chama a isto de «edições às cegas». Em termos de engenharia, isto é semelhante a um programador escrever código sem consultar as assinaturas das funções nem conhecer os tipos das variáveis. «Todos os engenheiros seniores da minha equipa tiveram experiências semelhantes em primeira mão», escreveu ela no seu relatório. «Já não se pode confiar no Claude para realizar tarefas de engenharia complexas.»
A queda de um rácio de leitura para edição de 6,6 para 2,0 não é apenas uma alteração nas métricas comportamentais; significa um colapso nas taxas de sucesso das tarefas. A complexidade dos repositórios de código modernos implica que qualquer modificação envolva dependências entre vários ficheiros. Ignorar a análise do contexto e proceder diretamente às alterações não conduz apenas a «respostas incorretas», mas sim a «alterações aparentemente corretas que provocam novos erros a jusante». O custo da correção desses erros excede em muito o de uma única resposta explícita incorreta.
O paradoxo de «poupar dinheiro»
Um dos conjuntos de números mais contraintuitivos de todo o incidente provém dos mesmos dados da issue do GitHub: A equipa de Stella Laurenzo viu os custos mensais de utilização da API Claude Code descerem drasticamente de 345 dólares em fevereiro de 2026 para uns impressionantes 42 121 dólares em março, o que representa um aumento de 122 vezes.
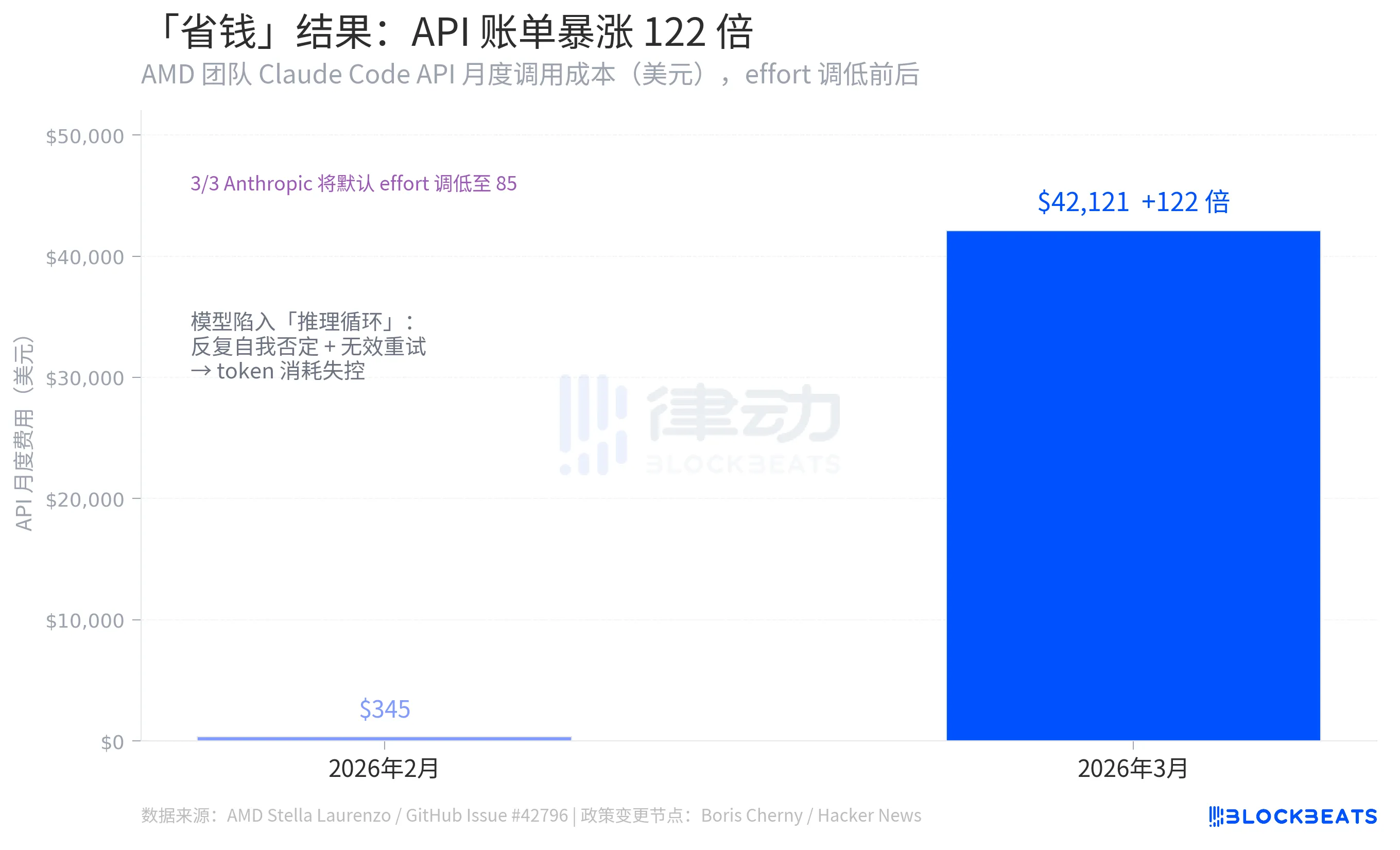
A lógica subjacente à redução de esforço da Anthropics consistiu em diminuir o consumo de tokens por chamada, reduzindo assim os custos. No entanto, o resultado foi o oposto. A razão por detrás disto foi o surgimento de inúmeros «ciclos de raciocínio» após a deterioração do modelo, o que levou a repetidas autonegações numa única resposta, reinícios constantes e um consumo de tokens muito superior à quantidade poupada. De acordo com os dados de Stella Laurenzo, a taxa de utilizadores que abandonam voluntariamente as tarefas aumentou 12 vezes durante o mesmo período, exigindo a intervenção contínua dos programadores, bem como correções e novos envios.
A lógica subjacente é um erro sistémico. Reduzir drasticamente a capacidade computacional numa tarefa complexa não implica, simplesmente, uma redução proporcional dos custos. Quando se desce abaixo de um determinado limiar de reflexão, o modelo começa a desviar-se do rumo, e o custo total acaba por aumentar. A redução do esforço permitiu poupar dinheiro em consultas simples, mas, nas tarefas de programação, fez a conta disparar.
Essa história do «emburrecimento», o GPT-4 já o fez há três anos
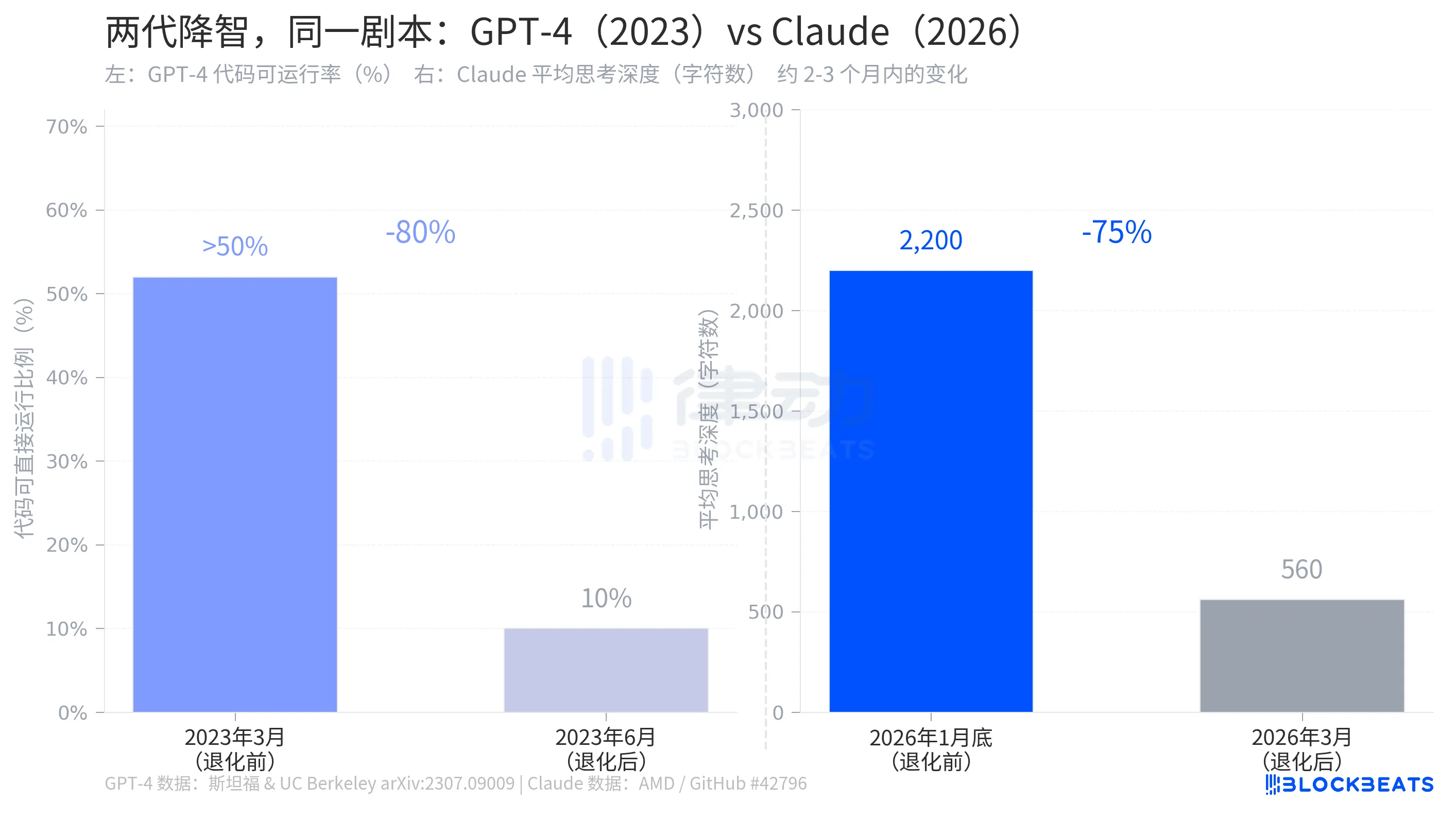
Em julho de 2023, uma equipa de investigação da Universidade de Stanford e da Universidade da Califórnia, em Berkeley, publicou um artigo no arXiv intitulado «Como está a mudar o comportamento do ChatGPT ao longo do tempo?», documentando o mesmo fenómeno a ocorrer no GPT-4.
De acordo com os dados da investigação, em março de 2023, o GPT-4 tinha gerado código em que mais de 50 % era diretamente executável. Em junho, essa proporção tinha descido para 10 %, o que representa uma redução de 80 % ao longo de três meses. Durante o mesmo período, a precisão na identificação de números primos desceu drasticamente de 97,6 % para 2,4 %. A resposta da OpenAI foi muito semelhante à da Anthropic: tinham sido realizadas otimizações em segundo plano, no âmbito do processo normal de iteração.
A estrutura das duas histórias é praticamente idêntica: uma empresa de IA ajustou discretamente, em segundo plano, os parâmetros que afetavam as capacidades do modelo; os utilizadores aperceberam-se disso; a empresa reconheceu o ajuste, mas explicou-o como uma «alocação de recursos mais razoável». A degradação do GPT-4 ocorreu em 2023, a do Claude em 2026, com três anos de diferença, mas o cenário é o mesmo.
Não se trata de um erro específico de uma determinada empresa. A lógica económica dos modelos de subscrição de IA determina que, quando os custos de raciocínio excedem os preços que podem ser cobrados, os fabricantes enfrentam a mesma pressão. Reduzir a intensidade de pensamento predefinida é, atualmente, a opção mais fácil de ajustar no equilíbrio entre custo e desempenho. O que os utilizadores percebem é que o modelo está a «ficar mais burro». O que o fabricante poupa na contabilidade é o custo marginal simbólico por chamada.
Boris Cherny disponibilizou uma solução técnica que permite aos utilizadores restaurar manualmente a intensidade do pensamento para o nível mais alto através do comando /effort high ou modificando o ficheiro de configuração. Esta solução é tecnicamente viável, mas também significa que o «máximo desempenho» já não é a configuração predefinida.
De 345 a 42 121 dólares, o que foi gasto não foi apenas o orçamento, mas também um pressuposto: as alterações de configuração padrão feitas pelo fabricante tinham como objetivo melhorar a experiência do utilizador.
Também poderá gostar de

Relatório Matinal | Coinbase Ventures realiza o seu primeiro investimento na ENA; SpaceX planeia definir o preço do IPO em 135 dólares por ação

Texto integral e análise do discurso do CEO da SanDisk na 42.ª Conferência Anual de Decisões Estratégicas da Bernstein

Previsão de Preço da Bitcoin para 2030: Ark Invest Prevê 710 mil dólares

Preço do SOL hoje: Preço da Solana em tempo real, gráficos e dados de mercado

O que é um ETF de Bitcoin: Spot vs. Futuros Explicado

Why Is Bitcoin Dropping 15% While Nasdaq Hits Record Highs?

O que é TradFi e porque é que todos falam sobre isso em 2026?

Relatório da Manhã | Strategy vendeu 32 BTC e mais de 800.000 ações da MSTR na semana passada; Binance anunciou oficialmente o seu portal de negociação de ações dos EUA; Polymarket estabeleceu uma parceria exclusiva com a OneFootball

Bootcamp de Trading WEEXPERIENCE na Polónia: Como a WEEX e a FireCrew estão a tornar o trading de cripto acessível a todos

Paris Reina Supremo: Como o PSG esmagou o sonho do Arsenal numa final histórica da UCL

TaiJi conclui financiamento estratégico de 3,5 milhões de dólares, com investimentos da Castrum Capital, Becker Ventures e Coinvestor Ventures

Bitcoin estagnado perto dos 73 mil dólares? Como os traders estão a encontrar recompensas num mercado lateral em junho

Como fazer staking de Solana: Um guia passo a passo para 2026

Preço Garantido já disponível na WEEX: Execute com maior precisão

A investigação mais recente do BIS: O futuro das stablecoins e o panorama monetário global
Entrevista com o mestre da macroeconomia Raoul Pal: A competição em IA está a dar origem a uma "singularidade económica"; não desista facilmente dos seus ativos nos próximos quatro anos

Why is Peter Thiel, behind Palantir, preparing an exit in Argentina?
